1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| import requests
from bs4 import BeautifulSoup
import csv
import time
url = "https://www.bilibili.com/v/popular/all"
response = requests.get(url)
html_content = response.content
soup = BeautifulSoup(html_content, "html.parser")
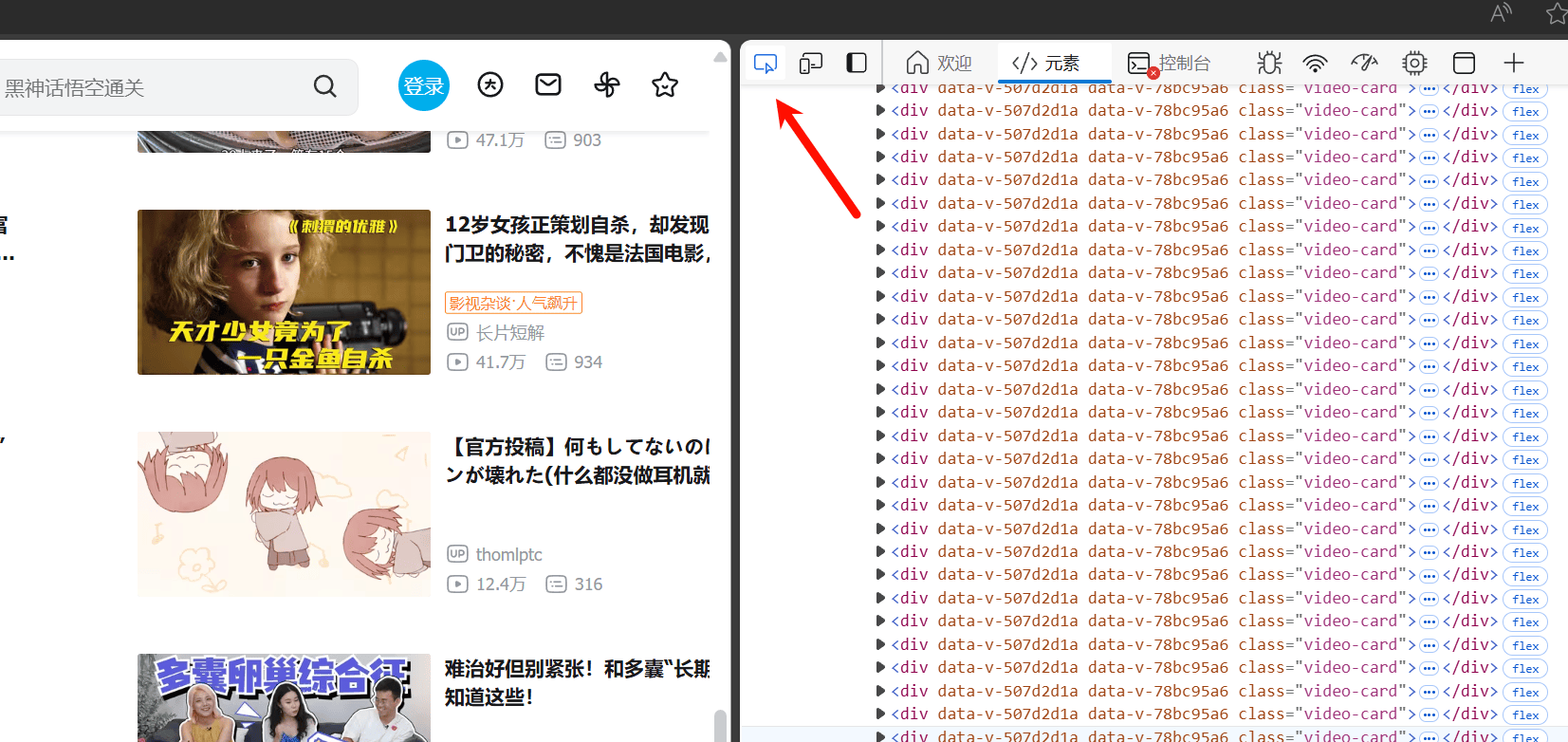
if not soup.find_all("div", class_="video-card"):
print("数据似乎是通过JavaScript动态加载的,需要进一步处理.")
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(url)
time.sleep(5)
html_content = driver.page_source
soup = BeautifulSoup(html_content, "html.parser")
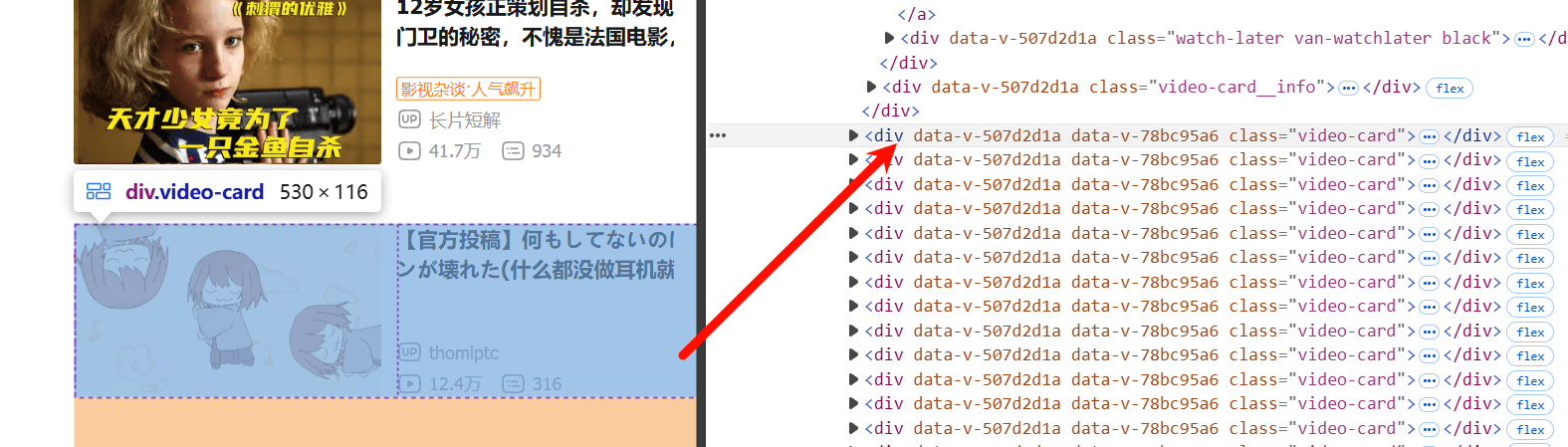
video_cards = soup.find_all("div", class_="video-card")
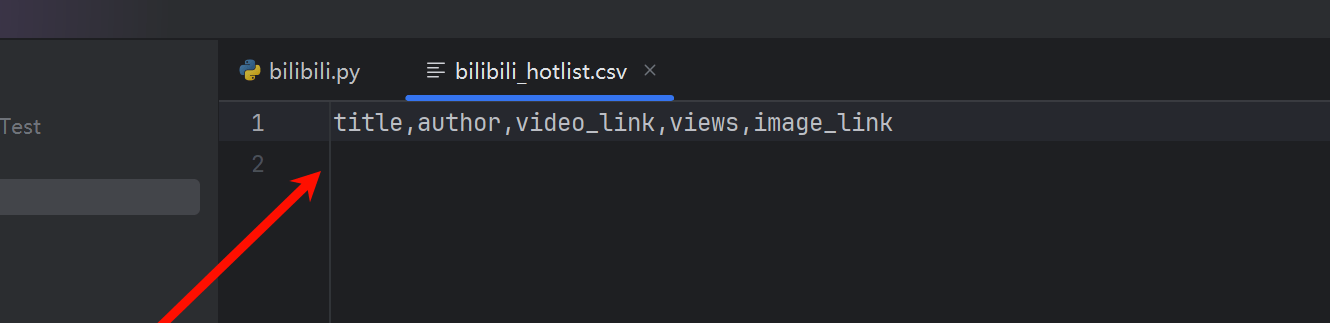
with open("bilibili_hotlist.csv", "w", newline="", encoding="utf-8") as csvfile:
fieldnames = ["title", "author", "video_link", "views", "image_link"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for video_card in video_cards:
title = video_card.find("p", class_="video-name").text.strip()
author = video_card.find("span", class_="up-name__text").text.strip()
video_link = "https://www.bilibili.com" + video_card.find("a")["href"]
views = video_card.find("span", class_="play-text").text.strip()
image_link = video_card.find("img", class_="cover-picture__image")["data-src"]
writer.writerow({
"title": title,
"author": author,
"video_link": video_link,
"views": views,
"image_link": image_link
})
print("数据已保存到 bilibili_hotlist.csv 文件中.")
|