一、处理Cookie
在有些需要处理Cookies是实现身份验证、会话保持和访问受限制内容的关键步骤。
Cookies是服务器发送给客户端的小数据片段,客户端会在后续请求中将它们发送回服务器。
1、手动设置Cookie
1
2
3
4
5
6
7
8
9
10
11
12
| import requests
headers = {
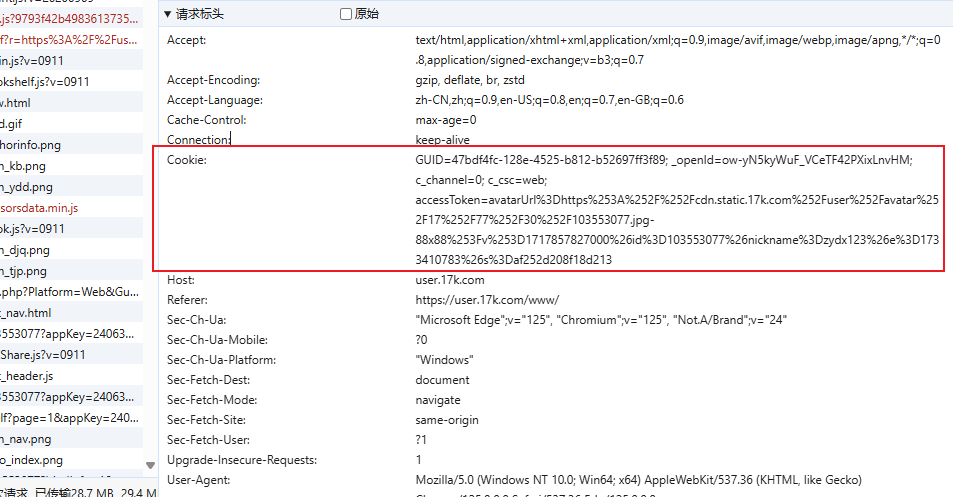
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/",
"Cookie": "GUID=47bdf4fc-128e-4525-b812-b52697ff3f89; _openId=ow-yN5kyWuF_VCeTF42PXixLnvHM; c_channel=0; "
"c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F17"
"%252F77%252F30%252F103553077.jpg-88x88%253Fv%253D1717857827000%26id%3D103553077%26nickname%3Dzydx123"
"%26e%3D1733410783%26s%3Daf252d208f18d213"
}
resp = requests.get("https://user.17k.com/ck/author2/shelf?page=1&appKey=2406394919",headers=headers)
print(resp.json())
|
2、使用Session管理
使用Python的requests库来模拟登录并获取Cookies,后续使用session发起请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| import requests
session = requests.Session()
data = {
"loginName": "zhanghao",
"password": "mima"
}
url = "https://passport.17k.com/ck/user/login"
response = session.post(url, data=data)
if response.status_code == 200:
print("登录成功")
else:
print("登录失败")
print("Cookies after login:")
print(session.cookies)
response = session.get("https://user.17k.com/ck/author2/shelf?page=1&appKey=2406394919")
print(response.text)
|
二、防盗链处理
1、防盗链现象
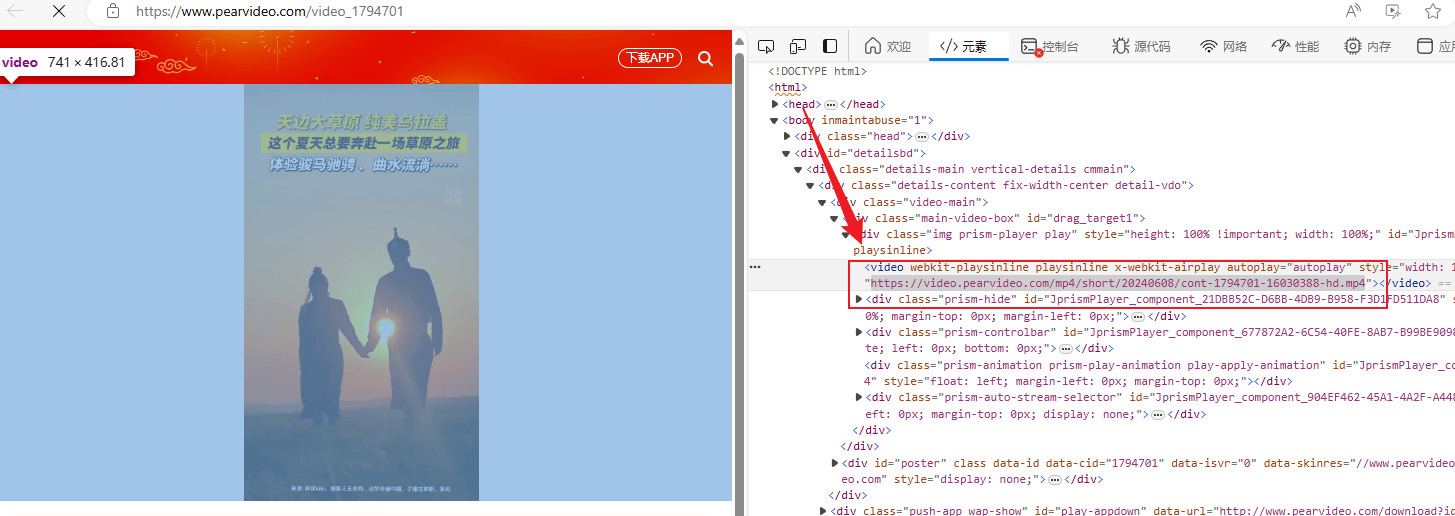
通过检查可以看见这个视频的URL链接,但是HTML源码中并没有这个链接。
查看网络请求,可以得到下面的内容:
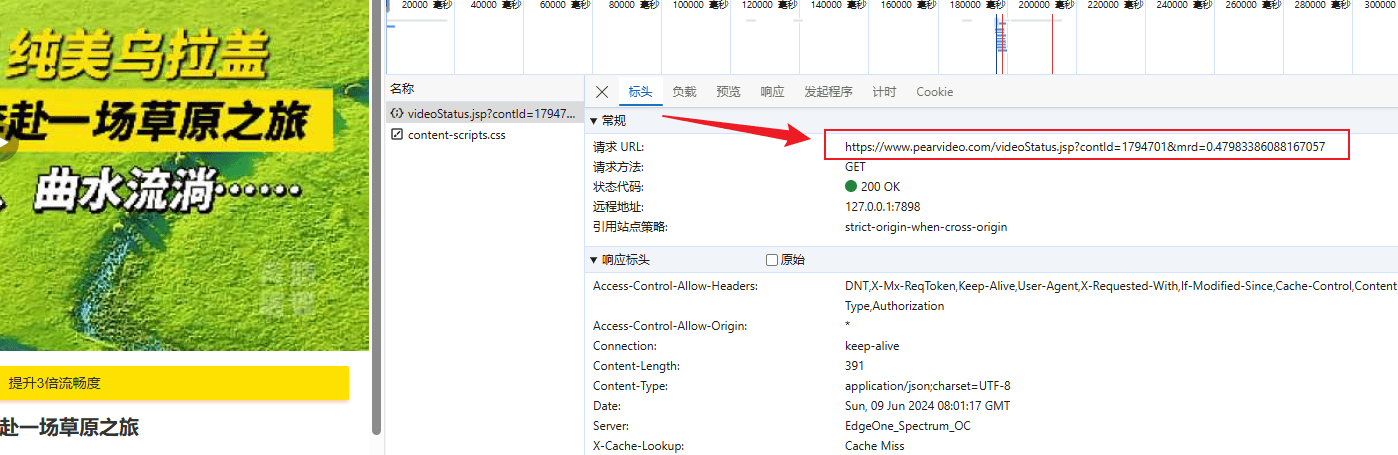
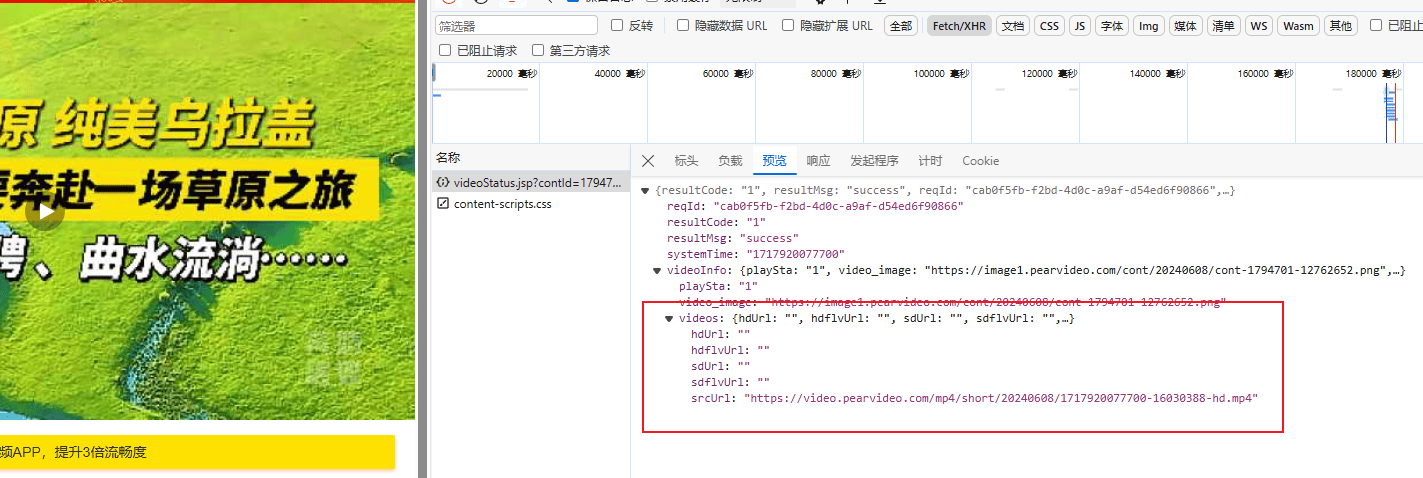
根据这个请求头的地址可以获得一些json信息,这些json信息中就包含了视频地址信息。
但是,如果直接访问这个请求地址:https://www.pearvideo.com/videoStatus.jsp?contId=1794701&mrd=0.47983386088167057

由于请求头中包含防盗链技术(referer),无法获取到正常情况下应该获取的JSON信息。


所以,要通过修改请求头中的referer来绕过防盗链技术,从而成功获取所需的JSON信息。
修改请求头:
1
2
3
4
5
6
7
| url = "https://www.pearvideo.com/video_1794701"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 "
"Safari/537.36 Edg/125.0.0.0",
"Referer": url
}
|
2、抓取梨视频
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import requests
url = "https://www.pearvideo.com/video_1794643"
contID = url.split("_")[1]
videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contID}&mrd=0.04365037843226749"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 "
"Safari/537.36 Edg/125.0.0.0",
"Referer": url
}
resp = requests.get(videoStatusUrl, headers=headers)
dic = resp.json()
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime, f"cont-{contID}")
with open(f"{contID}.mp4", "wb") as f:
f.write(requests.get(srcUrl).content)
|
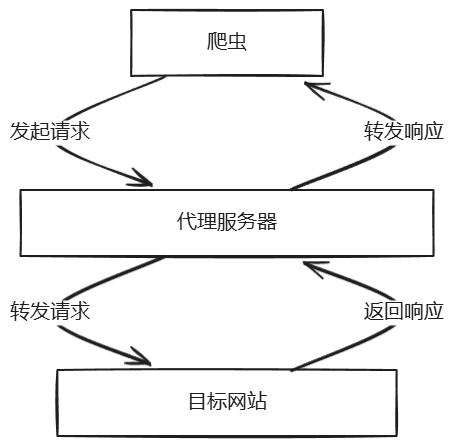
三、代理
代理的原理就是通过第三方的一个机器去发送请求,使用代理服务可以隐藏客户端的真实IP地址,绕过访问限制。
免费代理站: 免费代理IP站点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import requests
proxy = "http:110.86.183.16:59345"
proxies = {
"http": proxy,
"https": proxy,
}
url = "https://www.baidu.com"
response = requests.get(url, proxies=proxies)
print(response.text)
|
网上找的比较靠谱的代理API:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import requests
def get_proxy():
return requests.get("https://api.linux-do-proxy.com/get/").json()
def getHtml():
retry_count = 5
proxy = get_proxy().get("proxy")
while retry_count > 0:
try:
html = requests.get('http://www.example.com', proxies={"http": "http://{}".format(proxy)})
return html
except Exception:
retry_count -= 1
return None
|
