
子夜的星
终生学习者|阅读爱好者
解析数据
解析数据,除了前面的BeautifulSoup库,还有正则表达式和Xpath两种方法。
一、正则表达式
正则表达式(简称RE)是一种用来描述和匹配字符串模式的工具。
它广泛应用于文本处理、数据验证、文本搜索和替换等场景。正则表达式使用一种特殊的语法,可以对字符串进行复杂的模式匹配。
正则表达式测试:在线正则表达式测试
1、常用元字符
元字符:具有固定含义的特殊符号。每个元字符,默认只匹配一个字符串,并且不能匹配换行符。
| 元字符 | 描述 | 示例 |
|---|---|---|
. |
匹配除换行符以外的任意字符 | a.b 可以匹配 a1b、acb |
\w |
匹配字母、数字或下划线 | \w+ 匹配 hello、world_123 |
\s |
匹配任意的空白字符 | \s+ 匹配空格、制表符等 |
\d |
匹配数字 | \d+ 匹配 123、456 |
\n |
匹配一个换行符 | hello\nworld 匹配换行符 |
\t |
匹配一个制表符 | hello\tworld 匹配制表符 |
^ |
匹配字符串的开始 | ^Hello 匹配 Hello 开头的字符串 |
$ |
匹配字符串的结束 | World$ 匹配 World 结尾的字符串 |
\W |
匹配非字母、非数字、非下划线的字符 | \W+ 匹配 !@#、$%^ |
\D |
匹配非数字字符 | \D+ 匹配 abc、XYZ |
\S |
匹配非空白字符 | \S+ 匹配 hello、world123 |
| a | b | 匹配字符 a 或字符 b |
(...) |
捕获括号内的表达式,表示一个组 | (abc) 捕获 abc |
[...] |
匹配方括号中的任意字符 | [abc] 匹配 a、b 或 c |
[^...] |
匹配不在方括号中的任意字符 | [^abc] 匹配除 a、b、c 之外的任意字符 |
2、量词
量词:控制前面的元字符出现的次数
| 量词 | 描述 |
|---|---|
* |
重复零次或更多次 |
+ |
重复一次或更多次 |
? |
重复零次或一次 |
{n} |
重复n次 |
{n,} |
重复n次或更多次 |
{n,m} |
重复n到m次 |
惰性匹配.*?:尽可能少地匹配字符。在重复元字符后加 ? 实现惰性匹配。
贪婪匹配.*:尽可能多地匹配字符。默认的重复元字符都是贪婪的。
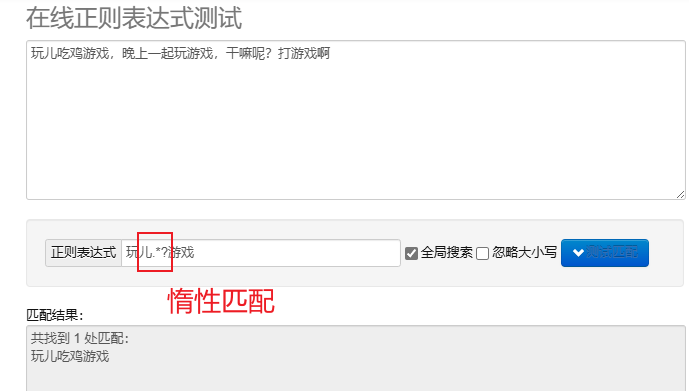
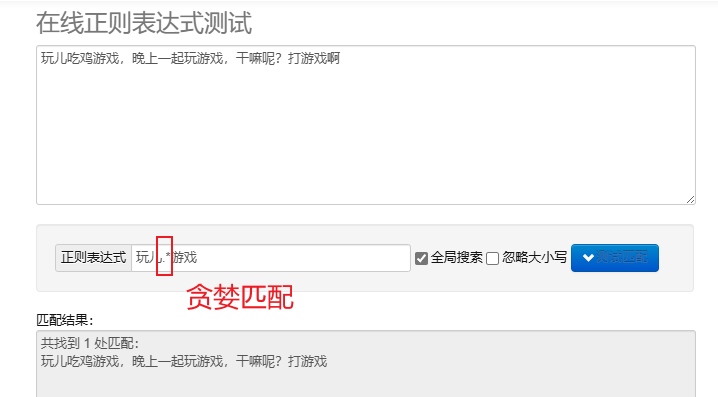
3、Re模块
在Python中使用处理正则表达式,可以使用 re 模块,这个模块提供了一系列用于搜索、匹配和操作字符串的函数。
| 函数 | 描述 |
|---|---|
re.search(pattern, string, flags=0) |
搜索字符串,返回第一个匹配的对象;若无匹配返回 None |
re.match(pattern, string, flags=0) |
从字符串起始位置匹配模式;若匹配成功返回匹配对象,否则 None |
re.fullmatch(pattern, string, flags=0) |
整个字符串完全匹配模式返回匹配对象,否则返回 None |
re.findall(pattern, string, flags=0) |
返回字符串中所有非重叠匹配的列表 |
re.finditer(pattern, string, flags=0) |
返回字符串中所有非重叠匹配的迭代器 |
re.sub(pattern, repl, string, count=0, flags=0) |
用替换字符串替换匹配模式的所有部分,返回替换后的字符串 |
re.split(pattern, string, maxsplit=0, flags=0) |
根据模式匹配分割字符串,返回分割后的列表 |
1 | import re |
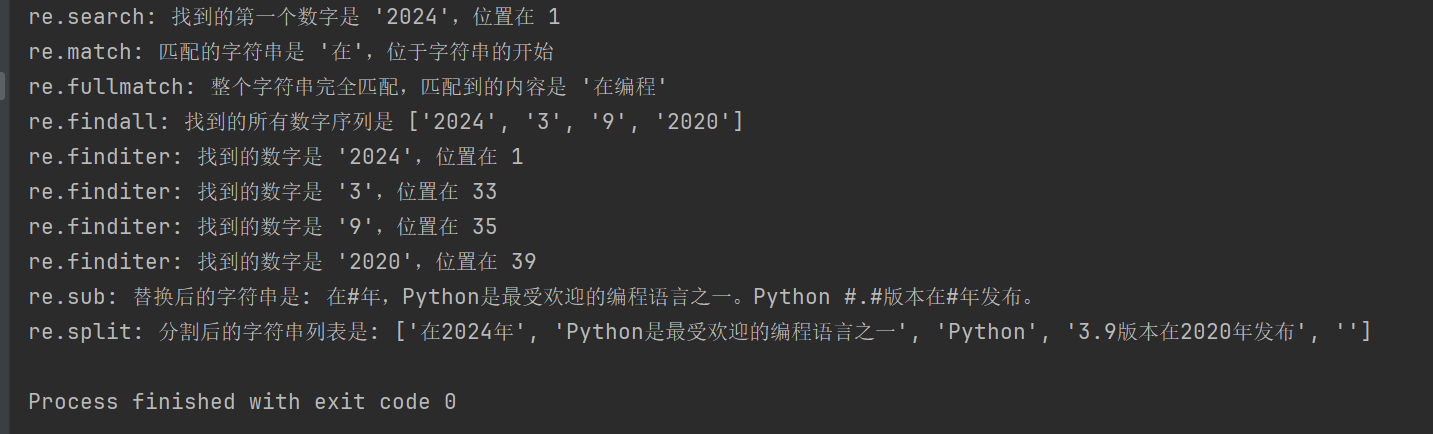
4、爬取豆瓣电影
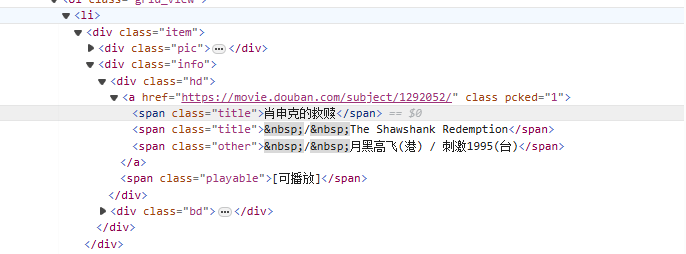
从<li>标签开始,逐步匹配到包含电影名的<span class="title">标签,使用非贪婪模式(.*?)匹配中间可能存在的任意字符,直到找到下一个明确的标记,用命名捕获组(?P<name>)提取出电影名部分。
Re表达式写法:
1 | <li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span> |
爬虫代码:
1 | import requests |
二、Xpath
Xpath是在XML文档中搜索的一门语言,它可以通过路径表达式来选择节点或节点集,HTML是XML的一个子集。
安装lxml模块: pip install lxml
1、Xpath解析
Ⅰ、节点选择
| 符号 | 解释 |
|---|---|
/ |
从根节点选择。 |
// |
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
. |
选择当前节点。 |
.. |
选择当前节点的父节点。 |
@ |
选择属性。 |
Ⅱ、路径表达式
| 表达式 | 解释 |
|---|---|
/bookstore/book |
选择bookstore节点下的所有book子节点。 |
//book |
选择文档中的所有book节点,不考虑它们的位置。 |
bookstore/book[1] |
选择bookstore节点下的第一个book子节点。 |
//title[@lang] |
选择所有具有lang属性的title节点。 |
//title[@lang='en'] |
选择所有lang属性为’en’的title节点。 |
Ⅲ、常用函数
text(): 选择元素的文本。@attr: 选择元素的属性。contains(): 判断包含关系。starts-with(): 判断开始部分。
1 | from lxml import etree |
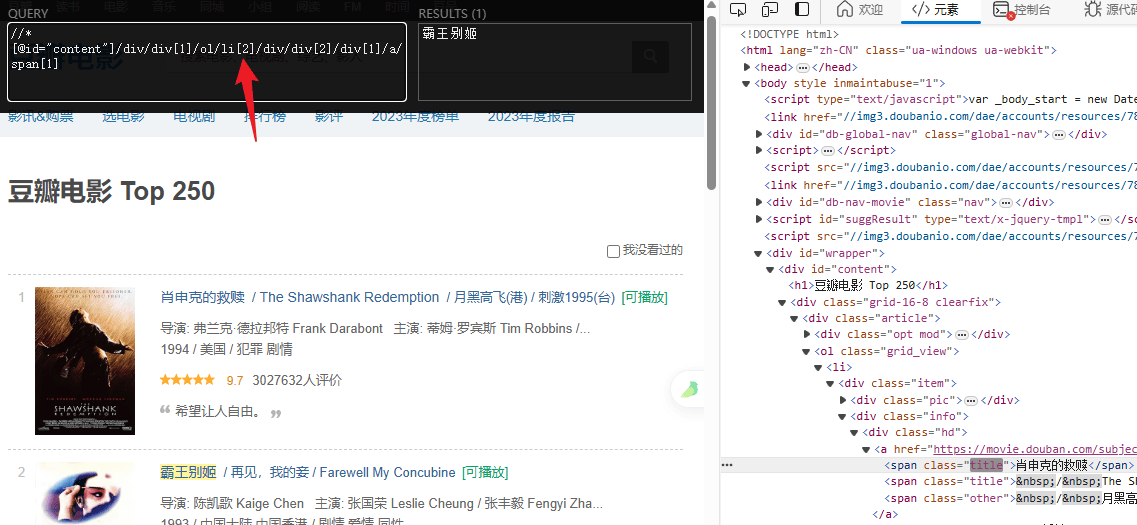
1 | //div[@class="movie"]/span[@class="title"][1]/text() |
//div[@class="movie"]:选择所有class为movie的div元素。
/span[@class="title"][1]:选择每个div中class为title的第一个span元素。
/text():获取span元素的文本内容。
1 | //div[@class="movie"]/span[@class="title"][2]/text() |
类似上述表达式,但选择的是每个div中class为title的第二个span元素。
2、爬取豆瓣电影
1 | import requests |