
一、常用命令
1、set和get
Redis 是按照键值对的方式存储数据的,get是根据 key来取 value,set是把 key和 value 存储进去。
set 使用命令:set key value

get 使用命令:get key

对于 Redis 命令,不区分大小写。如果 get 的 key 不存在,就会返回 nil,nil 表示为空。
2、keys
用来查询当前服务器上匹配的 key,通过一些通配符来描述一个 key 的模样,匹配上述模样的 key。
语法结构:keys pattern
pattern可以包括一些通配符:*(匹配任意数量的字符)、?(匹配任何单个字符)和 [](匹配括号内的任何一个字符)[^]表示排除某个字符。
虽然keys命令很实用,keys 的时间复杂度为keys *。这是因为keys命令会遍历整个键空间以查找与指定模式匹配的键,这可能会阻塞其他命令的执行,从而影响数据库的响应时间。
3、exists
语法结构:exists key
exists指令用于检查给定键是否存在于数据库中。它的语法很简单,只需要提供要检查的键名即可。如果键存在,则返回个数,如果键不存在,则返回整数0。
4、del
语法结构:del key
del 命令用于从Redis数据库中删除指定的键。它可以接受一个或多个键作为参数,并删除这些键及与之关联的任何数据。
5、expire
expire 命令用于为Redis中的键设置生存时间。
语法结构:expire key seconds
key:你要设置生存时间的键。seconds:键的生存时间,以秒为单位。
当键的生存时间到期后,Redis会自动删除该键。这个功能主要实现缓存、会话管理等功能。基于 Redis 实现分布式锁,为了避免出现不能正确解锁的情况,通常都会在加锁的时候设置一下过期的时间。如果想用毫秒,就使用 pexpire 命令
6、ttl
ttl 命令用于查询Redis中指定键的剩余生存时间,以秒为单位。这个命令非常有用,特别是在需要了解某个键的过期时间或调试缓存策略时。当使用 ttl命令时,它会返回以下几种情况之一:
-
正整数:表示键的剩余生存时间,以秒为单位。
-
-1:表示键存在但没有设置生存时间。
-
-2:表示键不存在。
7、type
语法结构:type key
type命令用于检查Redis中指定键的存储数据类型。
8、渐进式遍历
scan 是一种用于遍历数据库中所有键的命令。与传统的 keys 命令不同,scan 命令在遍历大数据集时更为高效,因为它可以在不阻塞服务器的情况下逐步返回结果。scan 命令非常适合处理大型数据集和避免阻塞的场景。
语法结构:scan cursor [MATCH pattern] [COUNT count]
-
cursor:游标,初始值为
0,表示遍历的起点。之后的每次调用都使用前一次调用返回的新游标,用户可以使用该值继续扫描。游标值为0表示扫描完成。 -
MATCH pattern:匹配模式,可选参数,用于过滤键。使用glob-style模式,例如
user:*匹配所有以user:开头的键。 -
COUNT count:数量,可选参数,提供一个提示,表示每次迭代应返回的键数。这只是一个提示,实际返回的键数可能会少于这个数量。
例如:
1 | 127.0.0.1:6379> SCAN 0 COUNT 3 |
命令解释:这个命令从游标 0 开始扫描数据库中的键,并建议(提示)每次返回最多 3 个键。
输出解释:
"5":这是返回的新的游标值,表示下一次扫描的起点。这个游标值不是0,说明扫描尚未完成,可以继续用新的游标值进行下一次扫描。- 键数组:
["keyx", "key", "mylist"]。这是本次扫描返回的键,数量可能少于或等于COUNT提示的数量(在此例中为3)。
二、常用数据类型
| 数据结构 | 内部编码 |
|---|---|
| 字符串 | int、embstr、raw |
| 哈希 | ziplist、hashtable |
| 列表 | ziplist、linkedlist、quicklist |
| 集合 | intset、hashtable |
| 有序集合 | ziplist、skiplist |
| Stream | listpack、radix tree |
-
字符串
-
int: 当字符串值是整数时使用 -
embstr: 针对短字符串的特殊优化 -
raw: 最基本的字符串
-
-
哈希
-
ziplist: 当哈希表中的键值对数量较少且每个键值对都很小的时候使用。 -
hashtable: 当哈希表中的键值对数量较多或其中某个键值对很大的时候使用。 -
列表
-
ziplist: 当列表元素数量较少且每个元素都很小的时候使用。 -
linkedlist: 早期版本中使用的双向链表(已被quicklist取代)。 -
quicklist: 现代 Redis 版本中默认使用的编码方式,它是ziplist和linkedlist的结合体,既节省空间又能高效操作。 -
集合
-
intset: 当集合中的所有元素都是整数且数量较少时使用。 -
hashtable: 当集合中包含非整数元素或元素数量较多时使用。 -
有序集合
-
ziplist: 当有序集合中的元素数量较少且每个元素都很小的时候使用。 -
skiplist: 当有序集合中的元素数量较多或某个元素很大的时候使用。 -
Stream
-
listpack: 用于存储小范围的压缩列表。 -
radix tree: 用于高效地管理和访问流中的数据。
1、String
在 Redis 中的字符串,直接就是按照二进制数据的方式存储的,不会做任何编码转换,存的是啥,取出来的就是啥。
Ⅰ、常用指令
| 命令 | 执行效果 |
|---|---|
set key value |
设置 key 的值是 value |
get key |
获取 key 的值 |
del key [key ...] |
删除指定的 key |
mset key value [key value ...] |
批量设置指定的 key 和 value |
mget key [key ...] |
批量获取 key 的值 |
incr key |
指定的 key 的值 +1 |
decr key |
指定的 key 的值 -1 |
incrby key n |
指定的 key 的值 +n |
decrby key n |
指定的 key 的值 -n |
incrbyfloat key n |
指定的 key 的值 +n (浮点数) |
append key value |
将 value 追加到 key 的原值之后 |
getrange key start end |
获取 key 的子字符串 |
setrange key offset value |
从指定位置开始用 value 覆盖 key |
strlen key |
获取 key 值的长度 |
setnx key value |
仅当 key 不存在时设置其值为 value |
setex key seconds value |
设置 key 的值并指定过期时间 (秒) |
psetex key milliseconds value |
设置 key 的值并指定过期时间 (毫秒) |
2、Hash
Redis 自身已是键值对结构了,Redis 自身的键值对就说通过 Hash 来组织的。

哈希类型种的映射关系通常称为 field-vaule,用于区分 Redis 整体键值对,这里的 value 是指 field 对应的值,不是键对应的值。
Ⅰ、常用指令
| 命令 | 执行效果 |
|---|---|
hset key field value |
设置值 |
hget key field |
获取值 |
hdel key field [field ...] |
删除 field |
hlen key |
计算 field 个数 |
hgetall key |
获取所有的 field-value |
hmget key field [field ...] |
批量获取 field-value |
hexists key field |
判断 field 是否存在 |
hkeys key |
获取所有的 field |
hvals key |
获取所有的 value |
hsetnx key field value |
设置值,但必须在 field 不存在时才能设置成功 |
hincrby key field n |
对应 field-value +n |
hincrbyfloat key field n |
对应 field-value +n |
hstrlen key field |
计算 value 的字符串长度 |
3、List
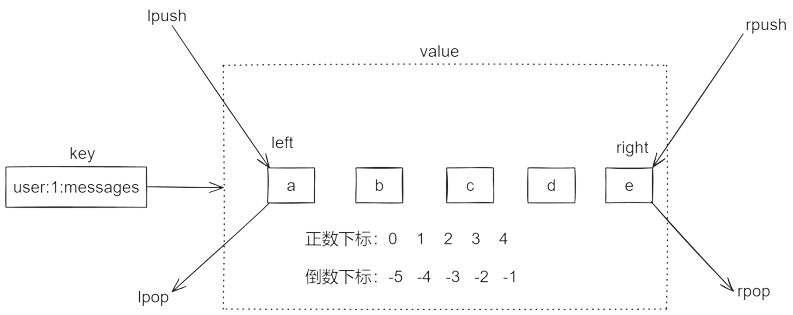
约定最左侧元素下标为 0,redis 的下标支持负数下标。list 内部的编码方式并非是一个简单的数组,而是更接近于“双端队列”。list 中的元素是允许重复的,像 hash 这样的类型,field 是不能重复的。
Ⅰ、常用指令
| 操作类型 | 命令 | 执行效果 |
|---|---|---|
| 添加 | rpush key value |
在列表的右侧(尾部)插入一个或多个值,返回列表的长度 |
| 添加 | lpush key value |
在列表的左侧(头部)插入一个或多个值,返回列表的长度 |
| 添加 | `linsert key before | after pivot value` |
| 查找 | lrange key start end |
返回列表中指定范围内的元素 |
| 查找 | lindex key index |
返回列表中指定索引位置的元素 |
| 查找 | llen key |
返回列表的长度 |
| 删除 | lpop key |
移除并返回列表的第一个元素 |
| 删除 | rpop key |
移除并返回列表的最后一个元素 |
| 删除 | lrem key count value |
移除列表中与 value 相等的元素,移除的数量由 count 参数指定 |
| 删除 | ltrim key start end |
对一个列表进行修剪,只保留指定范围内的元素 |
| 修改 | lset key index value |
将列表中指定索引位置的元素设置为新的值 |
| 阻塞操作 | blpop key timeout |
移出并获取列表的第一个元素,如果列表为空则阻塞,直到等待超时或有一个元素可以弹出 |
| 阻塞操作 | brpop key timeout |
移出并获取列表的最后一个元素,如果列表为空则阻塞,直到等待超时或有一个元素可以弹出 |
4、Set
集合就是把一些有关联的数据放到一起,集合中的元素是无序的、唯一的。
对于集合来说set:[1,2,3]和set:[3,2,1]是同一个集合,但是对于list来说list[1,2,3]和list:[3,2,1]是两个不同的list。
Ⅰ、常用指令
| 命令 | 执行效果 |
|---|---|
sadd key value |
添加值 |
smembers <key> |
取出该集合的所有值。 |
sismember <key> <value> |
判断集合 <key> 是否含有该 <value> 值,有 1,没有 0 |
scard <key> |
返回该集合的元素个数。 |
srem <key> <value1> <value2> |
删除集合中的某个元素。 |
spop <key> |
随机从该集合中吐出一个值。 |
srandmember <key> <n> |
随机从该集合中取出 n 个值。不从集合中删除。 |
smove <source> <destination> <value> |
把集合中的一个值从一个集合移动到另一个集合 |
sinter <key1> <key2> |
返回两个集合的交集元素。 |
sunion <key1> <key2> |
返回两个集合的并集元素。 |
sdiff <key1> <key2> |
返回两个集合的差集元素 (key1 中的,不包含 key2 中的) |
Ⅱ、编码方式
集合类型的内部编码有两种:
- intset(整数集合):当集合中的元素都是整数并且元素的个数小于
set-max-intset-entries配置时,Redis会选用intset来作为集合的内部实现,从而减少内存的使用。 - hashtable(哈希表):当集合元素类型无法满足intset的条件时,Redis会选择hashtable来作为集合的内部实现类。
5、Zset
有序集合,存储的是唯一的字符串元素,同时每个元素会关联一个浮点数类型的分值。有序集合提供了获取指定分数和元素范围查找、计算成员排名等功能。
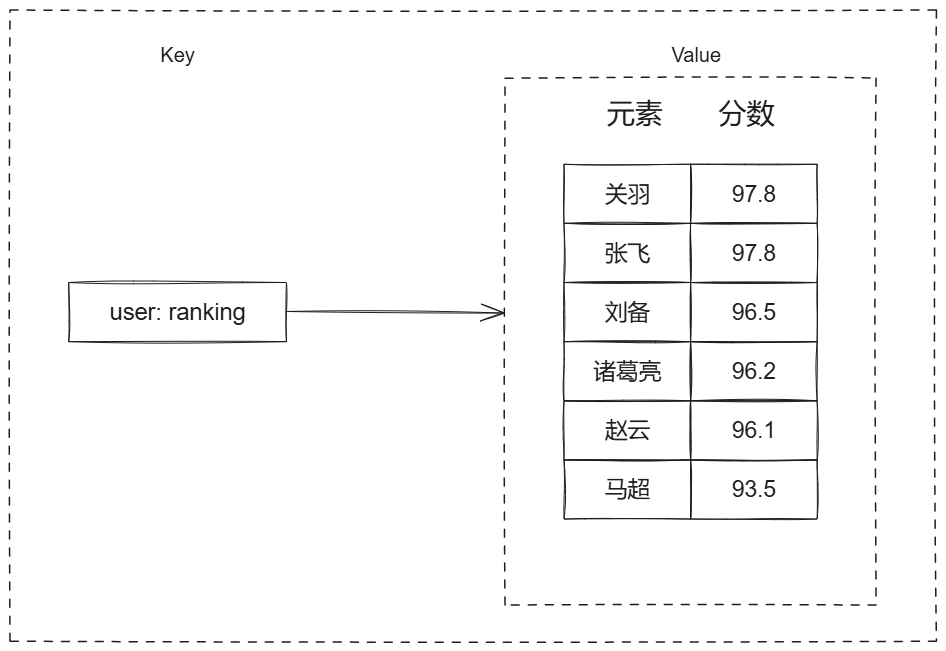
Ⅰ、常用指令
| 命令 | 执行效果 |
|---|---|
zadd key score member |
添加一个成员到有序集合中,或更新已存在成员的分数 |
zscore key member |
返回有序集中,成员的分数值 |
zincrby key increment member |
对有序集合中成员的分数加上增量 increment |
zcard key |
获取有序集合的成员数量 |
zcount key min max |
计算在有序集合中指定分数区间内的成员数量 |
zrange key start stop [withscores] |
返回有序集中,指定区间内的成员 |
zrevrange key start stop [withscores] |
返回有序集中,指定区间内的成员,按分数从高到低排序 |
zrangebyscore key min max [withscores] [limit offset count] |
返回有序集合中指定分数区间内的成员 |
zrevrangebyscore key max min [withscores] [limit offset count] |
返回有序集合中指定分数区间内的成员,按分数从高到低排序 |
zrank key member |
返回有序集合中指定成员的排名(从 0 开始)(按分数从低到高) |
zrevrank key member |
返回有序集合中指定成员的排名(按分数从高到低) |
zrem key member [member ...] |
从有序集合中移除一个或多个成员 |
zremrangebyrank key start stop |
移除有序集中,指定排名区间内的所有成员 |
zremrangebyscore key min max |
移除有序集中,指定分数区间内的所有成员 |
zrangebylex key min max [limit offset count] |
返回有序集合中指定成员字典区间内的成员 |
zlexcount key min max |
返回有序集合中指定成员字典区间内的成员数量 |
zremrangebylex key min max |
移除有序集合中指定成员字典区间内的成员 |
zscan key cursor [match pattern] [count count] |
迭代有序集合中的元素 |
zunionstore dest numkeys key [key ...] |
计算给定的一个或多个有序集的并集,并存储在新的 dest 集合中 |
zinterstore dest numkeys key [key ...] |
计算给定的一个或多个有序集的交集,并存储在新的 dest 集合中 |
Ⅱ、编码方式
有序集合(zset)的内部编码有两种:
-
ziplist(压缩列表):当有序集合的元素个数小于
zset-max-ziplist-entries配置(默认128个),且每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,Redis 会使用 ziplist 来实现有序集合。这可以有效减少内存的使用。 -
skiplist(跳表):当不满足 ziplist 条件时,有序集合会使用 skiplist 作为内部实现,因为在这种情况下 ziplist 的操作效率会下降。
三、Redis 客户端
导入jedis依赖:
1 | <dependency> |
1、端口转发
Redis端口直接开放,是很危险的。可以使用SSH的22端口,来传递其他端口的数据。使用SSH进行端口映射,将服务器的6379映射到本地的8888。
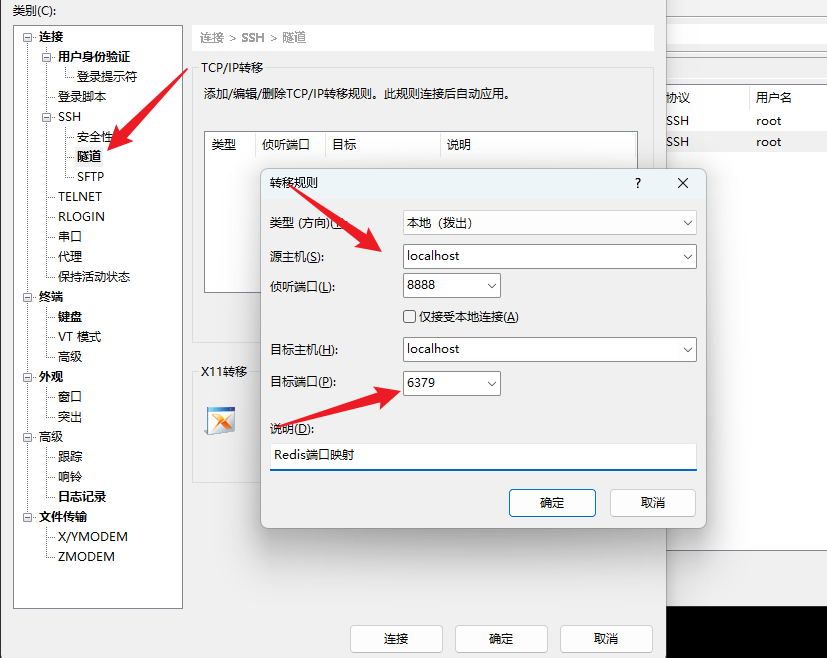
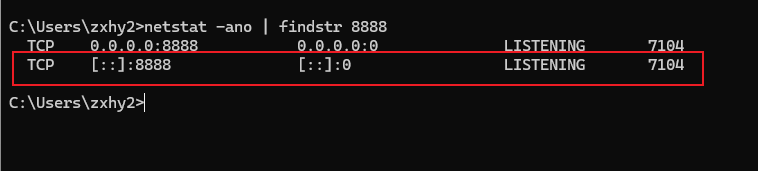
只有当SSH连接上了服务器,端口转发才生效。把SSH连接断开,端口转发就会失效。连接完成后,可以使用netstat命令看看本地的8888端口有没有被绑定。
1 | netstat -ano | findstr 8888 |
后续代码中,通过127.0.0.1:8888就可以访问到云服务器的Redis了,外面的客户端无法直接访问云服务器的6379
2、连接服务器
1 | public class RedisDemo { |
3、使用示例
使用Java的Jedis库操作Redis时,与直接在Redis CLI(命令行界面)中操作有一些不同,在Java中需要使用连接池来管理连接,避免频繁的连接创建和销毁。
1 | import redis.clients.jedis.Jedis; |